Sebagai seorang data analyst, menemukan waktu untuk mengerjakan proyek yang benar-benar berdampak bisa menjadi tantangan tersendiri. Sering kali, kita terjebak dalam tugas-tugas rutin yang menguras waktu produktif kita. Bayangkan berapa banyak insight berharga yang bisa Anda temukan jika tidak perlu menghabiskan berjam-jam untuk membuat laporan Excel yang sama setiap minggunya?
Artikel ini akan membahas 7 proyek Python yang tidak hanya meningkatkan keterampilan Anda, tetapi juga memberikan nilai nyata bagi bisnis. Sebagian besar proyek ini terinspirasi dari tantangan sehari-hari yang saya hadapi sebagai Data Analyst.
Benang merah dari semua proyek ini adalah: otomatiskan pekerjaan membosankan agar Anda memiliki waktu untuk mengerjakan hal-hal yang bernilai tinggi.
Mari kita mulai!
1. Mengotomatisasi Laporan Excel
Masalah:
Banyak organisasi menggunakan Excel secara ekstensif, dan itu untuk alasan yang baik. Excel familiar, fleksibel, dan memiliki antarmuka yang intuitif. Namun, ketika ditugaskan untuk membuat laporan yang sama secara berkala untuk berbagai kategori, klien, atau supplier, proses ini bisa sangat memakan waktu.
Tugas seperti copy-paste data, menerapkan format yang konsisten, memperbarui chart, memfilter berdasarkan kategori, dan menghasilkan beberapa versi laporan yang sama menghabiskan jam kerja berharga Anda.
Solusi:
Python sangat unggul dalam mengotomatisasi tugas-tugas berulang ini. Dengan library seperti pandas dan openpyxl, Anda dapat mengotomatisasi hampir setiap langkah:
- Memuat data secara otomatis dari berbagai sumber
- Membersihkan, mentransformasi, mengagregasi, dan membentuk ulang data
- Menerapkan format dan kode warna yang konsisten
- Menyisipkan chart dan pivot table
- Menghasilkan laporan yang disesuaikan secara massal
Contoh Implementasi:
python
import pandas as pd from openpyxl import Workbook from openpyxl.chart import BarChart, Reference import os # Load data df = pd.read_csv('sales_data.csv') # Group by region and calculate KPIs region_summary = df.groupby('region').agg({ 'revenue': 'sum', 'profit': 'sum', 'orders': 'count' }).reset_index() # Loop through each region to create separate reports for region in region_summary['region'].unique(): # Filter data for this region region_data = df[df['region'] == region] # Create a workbook for this region wb = Workbook() ws = wb.active ws.title = f"{region} Sales Report" # Add headers headers = ['Product', 'Revenue', 'Profit', 'Orders'] for col_num, header in enumerate(headers, 1): ws.cell(row=1, column=col_num).value = header # Add data product_summary = region_data.groupby('product').agg({ 'revenue': 'sum', 'profit': 'sum', 'orders': 'count' }).reset_index() for row_num, row_data in enumerate(product_summary.values, 2): for col_num, value in enumerate(row_data, 1): ws.cell(row=row_num, column=col_num).value = value # Create chart chart = BarChart() chart.title = f"{region} Revenue by Product" chart.x_axis.title = "Product" chart.y_axis.title = "Revenue" data = Reference(ws, min_col=2, min_row=1, max_row=len(product_summary)+1, max_col=2) cats = Reference(ws, min_col=1, min_row=2, max_row=len(product_summary)+1) chart.add_data(data, titles_from_data=True) chart.set_categories(cats) ws.add_chart(chart, "F2") # Save workbook if not os.path.exists('region_reports'): os.makedirs('region_reports') wb.save(f"region_reports/{region}_sales_report.xlsx") print("All regional reports generated successfully!")
Penjelasan kode:
- Kita memulai dengan memuat data dari CSV.
- Kemudian mengelompokkan data berdasarkan region dan menghitung KPI.
- Untuk setiap region, kita membuat workbook Excel terpisah.
- Dalam setiap workbook, kita menambahkan header dan data yang sesuai.
- Kita juga membuat chart batang untuk memvisualisasikan revenue berdasarkan produk.
- Terakhir, kita menyimpan setiap workbook ke folder khusus.
Mengapa Ini Berharga:
Ini mengurangi kerja manual, meminimalkan kesalahan manusia, dan membebaskan waktu Anda. Alih-alih menghabiskan berjam-jam untuk copy-paste dan formatting, Anda memberikan laporan yang bersih dan konsisten dalam hitungan detik.
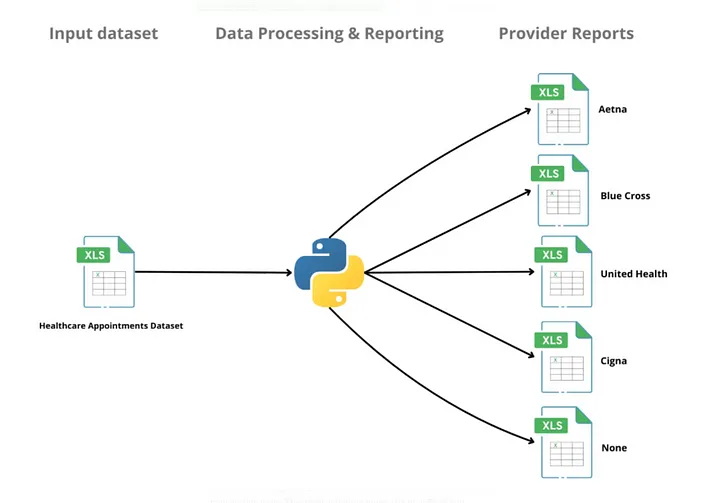
2. Menghasilkan Presentasi PowerPoint Otomatis
Masalah:
Sama seperti Excel, PowerPoint tetap menjadi kebutuhan di banyak tempat kerja. Banyak organisasi memiliki siklus evaluasi berkala untuk supplier, pelanggan, atau tim internal, yang seringkali membutuhkan struktur slide yang sama dengan angka yang diperbarui. Membuat presentasi secara manual, menyalin angka, memperbarui chart, dan memformat slide bukanlah tugas yang paling memuaskan.
Solusi:
Di Python, Anda dapat menggunakan kombinasi Python-pptx dan library pandas. Library Python-pptx memungkinkan Anda mengambil dua rute:
- Membangun dari awal — menulis script yang secara terprogram membuat semua elemen slide, seperti judul, chart, dan tabel, menyisipkan data dinamis dari file sumber Anda.
- Menggunakan template — mulai dengan file PowerPoint yang sudah didesain dan memperbarui placeholder atau bentuk tertentu dengan data baru, mempertahankan layout dan desain yang ada.
Cara kedua adalah favorit saya, karena Anda dapat menyerahkan desain kepada orang lain.
Contoh Implementasi:
python
from pptx import Presentation import pandas as pd import matplotlib.pyplot as plt from io import BytesIO # Load data sales_data = pd.read_csv('quarterly_sales.csv') # Create quarterly summary quarterly_summary = sales_data.groupby('quarter').agg({ 'revenue': 'sum', 'profit': 'sum', 'customer_count': 'sum' }).reset_index() # Load template presentation prs = Presentation('quarterly_report_template.pptx') # Update title slide title_slide = prs.slides[0] for shape in title_slide.shapes: if shape.has_text_frame: if "TITLE" in shape.text: shape.text = "Q2 2025 Sales Performance" if "SUBTITLE" in shape.text: shape.text = "Prepared by Data Analytics Team" # Update KPI slide kpi_slide = prs.slides[1] for shape in kpi_slide.shapes: if shape.has_text_frame: if "REVENUE" in shape.text: total_revenue = quarterly_summary['revenue'].sum() shape.text = f"Total Revenue: ${total_revenue:,.2f}" if "PROFIT" in shape.text: total_profit = quarterly_summary['profit'].sum() shape.text = f"Total Profit: ${total_profit:,.2f}" if "CUSTOMERS" in shape.text: total_customers = quarterly_summary['customer_count'].sum() shape.text = f"Total Customers: {total_customers:,}" # Create chart for slide 3 plt.figure(figsize=(10, 6)) plt.bar(quarterly_summary['quarter'], quarterly_summary['revenue']) plt.title('Revenue by Quarter') plt.xlabel('Quarter') plt.ylabel('Revenue ($)') plt.tight_layout() # Save chart to memory chart_buffer = BytesIO() plt.savefig(chart_buffer) plt.close() # Add chart to slide 3 chart_slide = prs.slides[2] chart_placeholder = None for shape in chart_slide.shapes: if shape.name == 'Chart_Placeholder': chart_placeholder = shape break if chart_placeholder: left = chart_placeholder.left top = chart_placeholder.top width = chart_placeholder.width height = chart_placeholder.height chart_placeholder.element.getparent().remove(chart_placeholder.element) chart_path = 'temp_chart.png' with open(chart_path, 'wb') as f: f.write(chart_buffer.getvalue()) chart_slide.shapes.add_picture(chart_path, left, top, width, height) # Save presentation prs.save('Q2_2025_Sales_Report.pptx') print("PowerPoint presentation generated successfully!")
Penjelasan kode:
- Kita memuat data penjualan dari CSV.
- Kita menghitung ringkasan kuartalan untuk KPI utama.
- Kita memuat template presentasi PowerPoint.
- Kita memperbarui slide judul dengan judul dan subjudul yang sesuai.
- Kita memperbarui slide KPI dengan nilai yang dihitung.
- Kita membuat chart menggunakan matplotlib dan menyimpannya ke dalam memori.
- Kita menambahkan chart ke slide yang sesuai, menggantikan placeholder.
- Terakhir, kita menyimpan presentasi yang sudah diperbarui.
Mengapa Ini Berharga:
Ini sangat bermanfaat bagi analis dan tim pelaporan yang mengelola update stakeholder di berbagai klien atau departemen. Mengotomatisasi proses ini meningkatkan efisiensi dan memungkinkan Anda untuk memperbesar dampak Anda melalui template yang standardisasi.
3. Ekstraksi Data Terstruktur dari PDF atau Gambar
Masalah:
PDF atau dokumen scan seperti invoice, purchase order, shipping label, dan laporan keuangan berisi data berharga. Dalam kasus di mana tidak ada pipeline data yang handal, file seperti ini bisa menjadi bottleneck dalam alur kerja analitik dan pelaporan, mengingat file-file tersebut dirancang untuk presentasi daripada analisis dan tidak langsung dapat dibaca oleh mesin.
Solusi:
Dengan Python, Anda dapat membangun alat yang mengekstrak data tabular dari PDF dan mengubahnya menjadi format terstruktur seperti CSV atau Excel. Library seperti pdfplumber atau PyMuPDF untuk membaca konten, dan pandas untuk membersihkan dan membentuk ulang data.
Contoh Implementasi:
python
import pdfplumber import pandas as pd import os def extract_tables_from_pdf(pdf_path): """ Extract tables from a PDF file and convert them to DataFrames """ all_tables = [] with pdfplumber.open(pdf_path) as pdf: # Go through each page for page_num, page in enumerate(pdf.pages, 1): # Extract tables from this page tables = page.extract_tables() # Process each table on this page for table_num, table in enumerate(tables, 1): if table: # Convert table to DataFrame df = pd.DataFrame(table[1:], columns=table[0]) # Add metadata df['source_page'] = page_num df['table_num'] = table_num all_tables.append(df) print(f"Extracted table {table_num} from page {page_num}") return all_tables # Directory with invoices invoice_dir = 'invoices/' output_dir = 'extracted_data/' # Create output directory if it doesn't exist if not os.path.exists(output_dir): os.makedirs(output_dir) # Process each invoice for filename in os.listdir(invoice_dir): if filename.endswith('.pdf'): print(f"Processing {filename}...") # Extract tables pdf_path = os.path.join(invoice_dir, filename) tables = extract_tables_from_pdf(pdf_path) if tables: # Combine all tables from this invoice combined_df = pd.concat(tables, ignore_index=True) # Clean the data # (In a real scenario, you would add more cleaning steps here) combined_df = combined_df.dropna(how='all') # Drop empty rows # Save as CSV output_name = os.path.splitext(filename)[0] + '.csv' output_path = os.path.join(output_dir, output_name) combined_df.to_csv(output_path, index=False) print(f"Saved extracted data to {output_path}") else: print(f"No tables found in {filename}") print("All invoices processed!")
Penjelasan kode:
- Kita mendefinisikan fungsi untuk mengekstrak tabel dari file PDF.
- Fungsi ini membuka PDF, memeriksa setiap halaman, dan mengekstrak tabel yang ditemukan.
- Setiap tabel dikonversi ke DataFrame pandas dengan metadata halaman dan nomor tabel.
- Kita memproses setiap file invoice dalam direktori tertentu.
- Untuk setiap invoice, kita mengekstrak semua tabel dan menggabungkannya menjadi satu DataFrame.
- Kita melakukan pembersihan dasar pada data.
- Terakhir, kita menyimpan data yang diekstrak ke file CSV.
Mengapa Ini Berharga:
Bekerja dengan data semi-terstruktur adalah tantangan dunia nyata, terutama dalam ekstraksi data dan digitalisasi dokumen. Anda dapat menjembatani kesenjangan antara dokumen yang berantakan dan dataset yang bersih, memungkinkan mereka digunakan untuk analisis satu kali atau dalam produk data.
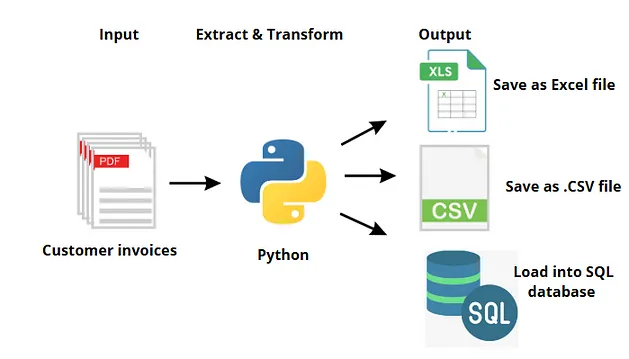
4. Otomatisasi Ekstraksi File Email
Masalah:
Anda akan terkejut betapa seringnya individu secara manual mengunduh lampiran berulang dari Outlook atau Gmail. Entah itu file performa mingguan, invoice, atau ekspor bulanan dari vendor, pencarian, pembukaan, dan penyimpanan file secara manual menyumbat alur kerja Anda dan meningkatkan risiko kesalahan manusia.
Solusi:
Dengan Python, Anda dapat mengotomatisasi seluruh proses. Menggunakan library win32com.client, Anda dapat terhubung ke inbox, mencari email berdasarkan subjek, pengirim, atau tanggal, mengunduh lampiran ke folder terstruktur, dan mengirim pengingat.
Contoh Implementasi:
python
import win32com.client import os from datetime import datetime, timedelta def extract_attachments_from_outlook( search_folder="Inbox", sender_contains="reports@company.com", subject_contains="Weekly Report", date_after=None, save_folder="extracted_reports" ): """ Extract attachments from Outlook emails matching specific criteria """ # Create output directory if it doesn't exist if not os.path.exists(save_folder): os.makedirs(save_folder) # Get current date if date_after not specified if date_after is None: date_after = datetime.now() - timedelta(days=7) # Connect to Outlook outlook = win32com.client.Dispatch("Outlook.Application") namespace = outlook.GetNamespace("MAPI") # Access the specified folder folder = namespace.GetDefaultFolder(6) # 6 = olFolderInbox if search_folder != "Inbox": try: folder = folder.Folders[search_folder] except: print(f"Folder '{search_folder}' not found. Using Inbox.") # Filter emails messages = folder.Items messages.Sort("[ReceivedTime]", True) # Sort by newest first # Find emails matching criteria extracted_count = 0 for message in messages: # Skip if message is older than date_after if message.ReceivedTime.date() < date_after.date(): continue # Check sender and subject filters if (sender_contains.lower() in message.SenderEmailAddress.lower() and subject_contains.lower() in message.Subject.lower()): # Process attachments for attachment in message.Attachments: # Generate unique filename with date received date_str = message.ReceivedTime.strftime("%Y%m%d") filename = f"{date_str}_{attachment.FileName}" save_path = os.path.join(save_folder, filename) # Save the attachment attachment.SaveAsFile(save_path) extracted_count += 1 print(f"Saved: {save_path}") print(f"Extraction complete. {extracted_count} attachments extracted.") return extracted_count # Run the extraction script extract_attachments_from_outlook( search_folder="Reports", sender_contains="analytics", subject_contains="Sales Report", date_after=datetime.now() - timedelta(days=30), save_folder="weekly_sales_reports" )
Penjelasan kode:
- Kita mendefinisikan fungsi untuk mengekstrak lampiran dari Outlook.
- Fungsi ini menerima parameter untuk memfilter email (folder, pengirim, subjek, tanggal).
- Kita terhubung ke Outlook menggunakan API win32com.client.
- Kita mengakses folder yang ditentukan (default: Inbox).
- Kita memfilter email berdasarkan kriteria yang diberikan.
- Untuk setiap email yang cocok, kita menyimpan semua lampirannya dengan nama file yang unik.
- Kita mengembalikan jumlah lampiran yang berhasil diekstrak.
Mengapa Ini Berharga:
Proyek ini mengajarkan Anda cara berinteraksi dengan layanan eksternal, seperti Microsoft Outlook, mengurai konten email, dan mengintegrasikan sumber data real-time ke dalam otomatisasi Anda. Ini juga membuka pintu untuk membangun alat back-office berbiaya pemeliharaan rendah, menggantikan tugas admin yang repetitif.
5. Membuat Portal Analitik Self-Service
Masalah:
Sebagian besar tim bergantung pada analis atau praktisi data lain untuk tugas berulang, termasuk yang diuraikan di atas: membuat laporan Excel, mengisi slide dengan data, atau mengekstrak data dari berbagai format. Meskipun tugas-tugas ini dapat diotomatisasi secara individual, mereka masih memerlukan seseorang untuk menjalankan script. Oleh karena itu, tantangan sebenarnya bukan hanya otomatisasi tetapi juga membuat otomatisasi itu dapat diakses oleh pengguna non-teknis.
Solusi:
Menggunakan Streamlit, Anda dapat membuat portal berbasis web dimana pengguna non-teknis dapat menghasilkan laporan - baik dengan memasukkan opsi filter, memungkinkan pengguna untuk memilih parameter sebelumnya dan menghasilkan laporan yang disesuaikan sesuai permintaan, atau memungkinkan pengguna untuk mengupload file dan menerima output yang siap pakai.
Anda dapat mengintegrasikan semua otomatisasi sebelumnya ke dalam satu platform yang kohesif:
- Upload PDF dan ekstrak tabel sebagai CSV yang bersih
- Upload data Excel mentah dan terima laporan yang diformat sepenuhnya
- Hasilkan presentasi PowerPoint yang diisi dengan chart dan KPI
- Bahkan memicu alur kerja berdasarkan file yang diterima melalui email
Contoh Implementasi:
python
import streamlit as st import pandas as pd import io from openpyxl import Workbook from openpyxl.chart import BarChart, Reference import pdfplumber from pptx import Presentation def process_excel_report(uploaded_file, region_filter=None): """Create formatted Excel report from raw data""" # Read uploaded file df = pd.read_excel(uploaded_file) # Apply region filter if provided if region_filter and region_filter != "All Regions": df = df[df['region'] == region_filter] # Group by product product_summary = df.groupby('product').agg({ 'revenue': 'sum', 'profit': 'sum', 'orders': 'count' }).reset_index() # Create Excel workbook in memory output = io.BytesIO() wb = Workbook() ws = wb.active ws.title = f"Sales Report" # Add headers headers = ['Product', 'Revenue', 'Profit', 'Orders'] for col_num, header in enumerate(headers, 1): ws.cell(row=1, column=col_num).value = header # Add data for row_num, row_data in enumerate(product_summary.values, 2): for col_num, value in enumerate(row_data, 1): ws.cell(row=row_num, column=col_num).value = value # Create chart chart = BarChart() chart.title = "Revenue by Product" chart.x_axis.title = "Product" chart.y_axis.title = "Revenue" data = Reference(ws, min_col=2, min_row=1, max_row=len(product_summary)+1, max_col=2) cats = Reference(ws, min_col=1, min_row=2, max_row=len(product_summary)+1) chart.add_data(data, titles_from_data=True) chart.set_categories(cats) ws.add_chart(chart, "F2") # Save to BytesIO wb.save(output) output.seek(0) return output def extract_pdf_tables(uploaded_file): """Extract tables from PDF""" tables_data = [] with pdfplumber.open(uploaded_file) as pdf: for page_num, page in enumerate(pdf.pages, 1): tables = page.extract_tables() for table_num, table in enumerate(tables, 1): if table: # Convert to DataFrame df = pd.DataFrame(table[1:], columns=table[0]) df['Page'] = page_num df['Table'] = table_num tables_data.append(df) return tables_data def create_powerpoint(data, title, subtitle): """Create PowerPoint presentation from data""" # Create presentation in memory output = io.BytesIO() # Use a simple template with 3 slides prs = Presentation() # Add title slide title_slide = prs.slides.add_slide(prs.slide_layouts[0]) title_slide.shapes.title.text = title title_slide.placeholders[1].text = subtitle # Add KPI slide kpi_slide = prs.slides.add_slide(prs.slide_layouts[1]) kpi_slide.shapes.title.text = "Key Performance Indicators" content = kpi_slide.placeholders[1] tf = content.text_frame tf.text = f"Total Revenue: ${data['revenue'].sum():,.2f}\n" tf.text += f"Total Profit: ${data['profit'].sum():,.2f}\n" tf.text += f"Total Orders: {data['orders'].sum():,}" # Save to BytesIO prs.save(output) output.seek(0) return output # Streamlit app st.title("Self-Service Analytics Portal") # Sidebar for navigation page = st.sidebar.selectbox( "Select Tool", ["Excel Report Generator", "PDF Data Extractor", "PowerPoint Generator"] ) if page == "Excel Report Generator": st.header("Excel Report Generator") uploaded_file = st.file_uploader("Upload your raw sales data (Excel)", type=["xlsx", "xls"]) if uploaded_file: # Preview the data df = pd.read_excel(uploaded_file) st.write("Data Preview:") st.dataframe(df.head()) # Get regions for filter if 'region' in df.columns: regions = ["All Regions"] + sorted(df['region'].unique().tolist()) region_filter = st.selectbox("Filter by Region:", regions) else: region_filter = None st.warning("No 'region' column found in the data.") if st.button("Generate Excel Report"): # Reset the file pointer to the beginning uploaded_file.seek(0) # Process the file output = process_excel_report(uploaded_file, region_filter) # Offer download st.download_button( label="Download Excel Report", data=output, file_name="sales_report.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" ) st.success("Report generated successfully!") elif page == "PDF Data Extractor": st.header("PDF Data Extractor") uploaded_file = st.file_uploader("Upload PDF with tables", type=["pdf"]) if uploaded_file: if st.button("Extract Tables"): tables = extract_pdf_tables(uploaded_file) if tables: st.write(f"{len(tables)} tables found in the PDF.") # Display each table for i, table_df in enumerate(tables): st.write(f"Table {i+1} (Page {table_df['Page'].iloc[0]}):") st.dataframe(table_df.drop(['Page', 'Table'], axis=1)) # Offer download for each table csv = table_df.to_csv(index=False).encode('utf-8') st.download_button( label=f"Download Table {i+1} as CSV", data=csv, file_name=f"table_{i+1}.csv", mime="text/csv" ) else: st.error("No tables found in the PDF.") elif page == "PowerPoint Generator": st.header("PowerPoint Generator") uploaded_file = st.file_uploader("Upload your sales data (Excel)", type=["xlsx", "xls"]) if uploaded_file: # Preview the data df = pd.read_excel(uploaded_file) st.write("Data Preview:") st.dataframe(df.head()) # Get presentation details title = st.text_input("Presentation Title", "Sales Report") subtitle = st.text_input("Presentation Subtitle", "Prepared by Data Analytics Team") if st.button("Generate PowerPoint"): output = create_powerpoint(df, title, subtitle) # Offer download st.download_button( label="Download PowerPoint", data=output, file_name="sales_presentation.pptx", mime="application/vnd.openxmlformats-officedocument.presentationml.presentation" ) st.success("PowerPoint generated successfully!")
Penjelasan kode:
- Kita membuat aplikasi Streamlit dengan tiga fitur utama: pembuat laporan Excel, pengekstrak data PDF, dan pembuat PowerPoint.
- Untuk pembuat laporan Excel, pengguna dapat mengupload file Excel mentah, memfilter berdasarkan region, dan menghasilkan laporan yang diformat dengan chart.
- Untuk pengekstrak data PDF, pengguna dapat mengupload file PDF dan mengekstrak tabel menjadi CSV.
- Untuk pembuat PowerPoint, pengguna dapat mengupload data penjualan, memasukkan judul dan subjudul, dan menghasilkan presentasi dengan slide KPI.
- Semua output dihasilkan dalam memori dan ditawarkan untuk diunduh.
Mengapa Ini Berharga:
Proyek seperti ini mewakili solusi end-to-end yang sebenarnya. Ini menghemat waktu bagi pengguna bisnis dan menghilangkan tekanan dari tim data atau pengembangan. Alih-alih bergantung pada analis untuk menjalankan script atau menghasilkan file, pengguna bisa mendapatkan apa yang mereka butuhkan secara instan. Ini adalah cara yang skalabel untuk memberdayakan tim non-teknis dan membiarkan profesional data fokus pada pekerjaan dengan dampak lebih tinggi.
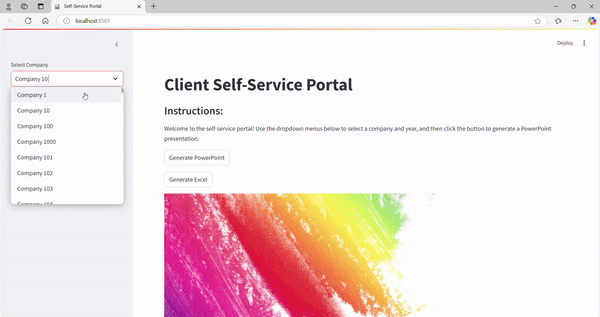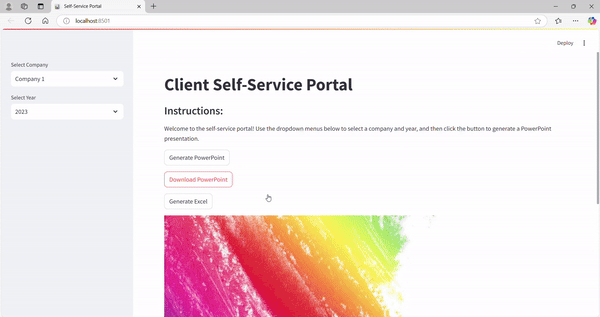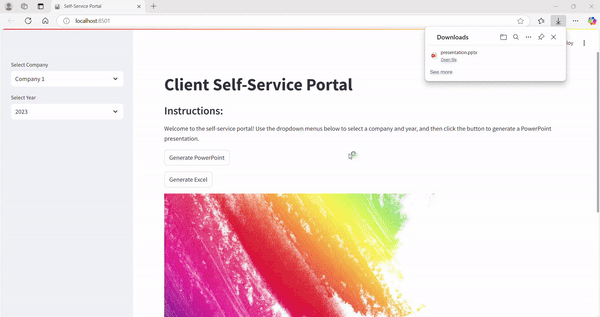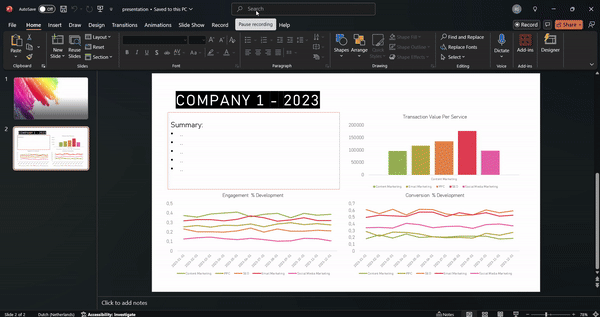
6. Membangun Pipeline Data Web & Cloud yang Skalabel
Masalah:
Data terstruktur dan dapat diakses adalah kunci untuk analisis, pelaporan, dan machine learning. Namun, data jarang diberikan kepada Anda dalam keadaan siap pakai. Misalnya, daftar produk kompetitor secara teknis tersedia di situs web mereka, tetapi datanya tidak terstruktur dan tersebar di berbagai halaman.
Solusi:
Dengan Python, Anda dapat membangun pipeline data yang skalabel menggunakan Scrapy, framework web scraping yang cepat dan fleksibel yang dirancang untuk skalabilitas, yang lebih powerful dari alat ringan seperti BeautifulSoup.
Pipeline tipikal meliputi:
- Ekstraksi data dari sumber web menggunakan alat seperti Scrapy
- Transformasi dan pembersihan data menggunakan pandas
- Memuat data yang telah diproses ke solusi penyimpanan cloud seperti Google BigQuery
Contoh Implementasi:
python
# scrapy_spider.py import scrapy from scrapy.crawler import CrawlerProcess class ProductSpider(scrapy.Spider): name = "products" start_urls = ["https://example-store.com/products"] def parse(self, response): # Extract product listings for product in response.css('div.product-item'): yield { 'name': product.css('h3.product-name::text').get(), 'price': product.css('span.price::text').get(), 'category': product.css('span.category::text').get(), 'rating': product.css('div.rating::attr(data-rating)').get(), 'url': product.css('a.product-link::attr(href)').get(), } # Follow pagination links next_page = response.css('a.next-page::attr(href)').get() if next_page: yield response.follow(next_page, self.parse) # data_pipeline.py import pandas as pd from google.cloud import bigquery from google.oauth2 import service_account import json import os from datetime import datetime def transform_data(input_file): """Clean and transform scraped data""" # Load the scraped data with open(input_file, 'r') as f: data = json.load(f) # Convert to DataFrame df = pd.DataFrame(data) # Clean price column (remove currency symbol, convert to float) df['price'] = df['price'].str.replace('$', '').str.replace(',', '').astype(float) # Clean missing values df['rating'] = pd.to_numeric(df['rating'], errors='coerce') df = df.dropna(subset=['name', 'price']) # Remove rows with missing name or price # Add metadata df['extraction_date'] = datetime.now().strftime('%Y-%m-%d') return df def load_to_bigquery(df, project_id, dataset_id, table_id): """Load data to BigQuery""" # Set up credentials credentials = service_account.Credentials.from_service_account_file( 'credentials.json' ) # Initialize client client = bigquery.Client(credentials=credentials, project=project_id) # Define table reference table_ref = f"{project_id}.{dataset_id}.{table_id}" # Load data job_config = bigquery.LoadJobConfig( write_disposition="WRITE_TRUNCATE", # Overwrite if exists schema=[ bigquery.SchemaField("name", "STRING"), bigquery.SchemaField("price", "FLOAT"), bigquery.SchemaField("category", "STRING"), bigquery.SchemaField("rating", "FLOAT"), bigquery.SchemaField("url", "STRING"), bigquery.SchemaField("extraction_date", "DATE"), ] ) job = client.load_table_from_dataframe(df, table_ref, job_config=job_config) job.result() # Wait for job to complete print(f"Loaded {len(df)} rows to {table_ref}") def run_pipeline(): """Run the complete ETL pipeline""" # 1. Extract - Run the spider output_file = 'scraped_products.json' process = CrawlerProcess(settings={ 'FEED_FORMAT': 'json', 'FEED_URI': output_file }) process.crawl(ProductSpider) process.start() # The script will block here until the crawling is finished # 2. Transform df = transform_data(output_file) print(f"Transformed data: {len(df)} rows") # 3. Load load_to_bigquery( df, project_id='my-analytics-project', dataset_id='competitor_data', table_id='products' ) print("Pipeline completed successfully!") if __name__ == "__main__": run_pipeline()
Penjelasan kode:
- Kita membuat spider Scrapy untuk mengekstrak data produk dari situs web.
- Spider ini mengumpulkan informasi nama, harga, kategori, rating, dan URL untuk setiap produk.
- Spider juga menangani paginasi untuk mengumpulkan semua halaman produk.
- Fungsi transform_data memuat data yang di-scrape, membersihkannya, dan mengubahnya menjadi format yang konsisten.
- Fungsi load_to_bigquery memuat data yang telah ditransformasi ke Google BigQuery.
- Fungsi run_pipeline menjalankan seluruh pipeline dari ekstraksi hingga pemuatan.
Mengapa Ini Berharga:
Proyek ini membantu untuk mendapatkan data yang dihasilkan di luar bisnis melalui pipeline end-to-end. Aktivitas kompetitor, tren harga, atau benchmark industri semuanya dapat dilacak tanpa perlu pihak ketiga.
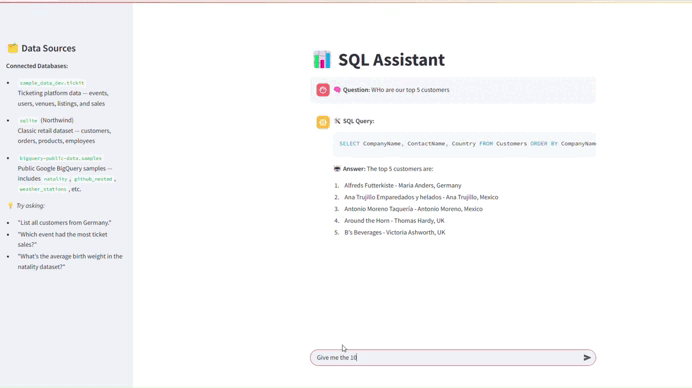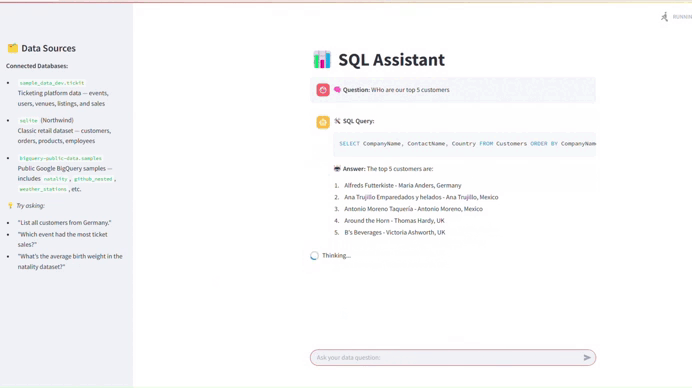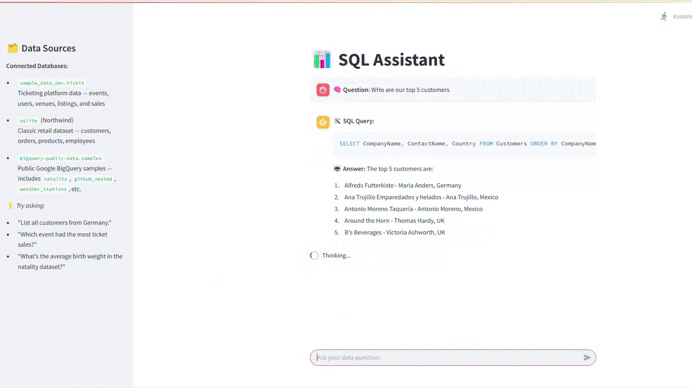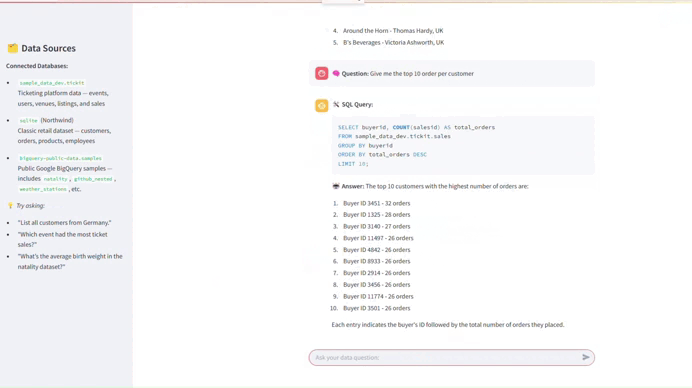
7. Membangun Asisten SQL Bahasa Alami
Masalah:
Anggota tim non-teknis sering kesulitan mendapatkan insight dari data. Di banyak perusahaan, data cenderung tersebar di berbagai database dan memerlukan pengetahuan SQL untuk mengaksesnya. Ini menciptakan masalah dua sisi: staf non-teknis bergantung pada staf teknis, dan staf teknis dibanjiri permintaan ad-hoc.
Solusi:
Dengan library seperti LangChain, Langgraph, dan Streamlit, Anda dapat membuat chatbot Retrieval-Augmented Generation (RAG) yang memungkinkan pengguna mengetik pertanyaan menggunakan bahasa alami dan mendapatkan jawaban yang akurat. Sistem RAG memanfaatkan model bahasa besar (LLM) dan menggunakan konteks bisnis untuk memahami pertanyaan pengguna dan menghasilkan query SQL terhadap sumber data yang benar.
Contoh Implementasi (Pseudocode):
python
import streamlit as st from langchain.chat_models import ChatOpenAI from langchain.schema import SystemMessage, HumanMessage import sqlite3 import pandas as pd # Initialize SQLite connection conn = sqlite3.connect('sales_data.db') # Function to execute SQL query and return results def execute_query(query): try: df = pd.read_sql_query(query, conn) return df, None except Exception as e: return None, str(e) # Function to get database schema def get_schema(): cursor = conn.cursor() tables = cursor.execute("SELECT name FROM sqlite_master WHERE type='table';").fetchall() schema_info = [] for table in tables: table_name = table[0] columns = cursor.execute(f"PRAGMA table_info({table_name});").fetchall() columns_info = [f"{col[1]} ({col[2]})" for col in columns] schema_info.append(f"Table: {table_name}, Columns: {', '.join(columns_info)}") return "\n".join(schema_info) # LLM integration def generate_sql(question, schema): llm = ChatOpenAI(model_name="gpt-3.5-turbo") system_prompt = f""" You are an expert SQL assistant. Your task is to convert natural language questions into SQL queries. Here's the database schema: {schema} Based on this schema, convert the user's question into a valid SQL query that would answer their question. Only respond with the SQL query, nothing else. """ messages = [ SystemMessage(content=system_prompt), HumanMessage(content=question) ] response = llm.invoke(messages) return response.content # Streamlit UI st.title("Natural Language SQL Assistant") question = st.text_input("Ask a question about your data:", value="What were the total sales in each region last month?") if question: schema = get_schema() with st.spinner("Generating SQL..."): sql_query = generate_sql(question, schema) st.code(sql_query, language="sql") if st.button("Run Query"): with st.spinner("Executing query..."): results, error = execute_query(sql_query) if error: st.error(f"Error executing query: {error}") else: st.write("Results:") st.dataframe(results)
Penjelasan kode:
- Kita membuat aplikasi Streamlit untuk antarmuka pengguna.
- Kita menghubungkan ke database SQLite yang berisi data penjualan.
- Kita mengambil skema database untuk memberikan konteks kepada model bahasa.
- Ketika pengguna memasukkan pertanyaan, kita mengirimkannya ke LLM bersama dengan skema database.
- LLM menghasilkan query SQL yang sesuai dengan pertanyaan.
- Pengguna dapat melihat dan menjalankan query SQL yang dihasilkan.
- Hasil query ditampilkan dalam bentuk tabel.
Mengapa Ini Berharga:
Proyek ini menghilangkan hambatan teknis untuk akses data, memberdayakan semua orang untuk membuat keputusan berdasarkan informasi tanpa menunggu analis atau menulis SQL. Ini juga mengurangi tekanan pada tim data dengan secara dramatis mengurangi volume permintaan ad-hoc. Yang lebih penting, ini mengintegrasikan model bahasa besar dengan database produksi langsung, keterampilan yang sangat dicari dalam tim data modern.
Pikiran Akhir & Tips
Seperti disebutkan di awal, proyek-proyek ini diambil dari tantangan nyata yang terinspirasi oleh pekerjaan. Oleh karena itu, saya memiliki beberapa pikiran penutup dan tips saat Anda mulai mengerjakan proyek Anda sendiri:
- Mulai kecil, deploy cepat. Jangan menunggu kesempurnaan. Bangun versi minimum, publikasikan, lalu tingkatkan.
- Otomatisasi yang dapat diprediksi, berulang dan statis. Fokus pada tugas berulang yang memakan waktu terlalu lama dan jarang berubah, itulah buah rendah Anda.
- Bersikap realistis dengan stakeholder. Jika Anda mengotomatisasi laporan statis, komunikasikan dengan jelas bahwa kustomisasi yang sering akan mengalahkan tujuan otomatisasi, karena Anda akan terus menyesuaikan kode Anda untuk item wishlist terbaru.
- Keamanan yang utama. Jika Anda mengerjakan setup lanjutan seperti pipeline web scraping atau asisten SQL bahasa alami (proyek 6 dan 7), perhatikan API key, privasi data, dan kontrol akses. Simpan kredensial sensitif dengan aman dan audit penggunaan jika diperlukan.
Glossary:
- ETL (Extract, Transform, Load): Proses yang melibatkan ekstraksi data dari sumber, transformasi data ke format yang sesuai, dan pemuatan data ke dalam sistem target seperti data warehouse.
- Web Scraping: Teknik mengekstrak data dari situs web, biasanya dengan mengotomatisasi proses pengumpulan data yang biasanya dilakukan secara manual.
- API (Application Programming Interface): Set aturan yang memungkinkan program berkomunikasi dengan program lain, memungkinkan integrasi dan pertukaran data.
- DataFrame: Struktur data 2D berlabel dengan kolom yang dapat berisi jenis data yang berbeda, umumnya digunakan dalam pandas untuk manipulasi dan analisis data.
- PowerPoint Automation: Proses mengotomatisasi pembuatan dan pembaruan presentasi PowerPoint menggunakan perangkat lunak atau skrip.
- RAG (Retrieval-Augmented Generation): Teknik yang menggabungkan kemampuan pencarian dengan model generatif untuk meningkatkan kualitas dan akurasi respons yang dihasilkan.
- LLM (Large Language Model): Model AI yang dilatih pada dataset teks besar yang dapat menghasilkan dan memahami bahasa manusia, seperti GPT-3.5 atau GPT-4.
- Data Pipeline: Serangkaian proses atau langkah yang terkoordinasi untuk memindahkan data dari satu sistem ke sistem lain, mungkin termasuk langkah ekstraksi, transformasi, dan pemuatan.
- Self-Service Analytics: Pendekatan untuk data analytics di mana pengguna non-teknis dapat mengakses dan bekerja dengan data tanpa bergantung pada pakar analitik atau TI.
- Dashboard: Tampilan visual informasi, biasanya melacak dan menampilkan KPI, metrik, dan titik data utama secara real-time untuk memantau kesehatan bisnis
Citations:
- https://www.wscubetech.com/blog/data-analytics-project-ideas/
- https://blog.devgenius.io/how-to-automate-excel-data-analysis-with-python-788cb966344
- https://www.linkedin.com/pulse/3-python-scripting-pdf-extraction-credit-card-isaac-mart%C3%ADnez-barcia-toyhc
- https://www.linkedin.com/pulse/extracting-email-attachments-from-outlook-pst-files-using-umer-saeed-vxmyf
- https://www.fabi.ai/blog/introducing-analyst-agent-deploy-custom-ai-agents-for-self-service-analytics-in-minutes
- https://blog.myskill.id/istilah-dan-tutorial/mengenal-common-table-expressions-cte-dalam-data-analysis/
- https://learn.microsoft.com/id-id/sql/t-sql/queries/with-common-table-expression-transact-sql?view=sql-server-ver16
- https://www.c-sharpcorner.com/article/optimizing-sql-queries-cte-vs-temporary-tables-for-speed/
- https://dqlab.id/ilmu-data-science-untuk-kelola-keuangan-yang-bijaksana
- https://dqlab.id/belajar-data-analyst-project-baru-dqlab
- https://tugu.com/artikel/kelola-keuangan-pribadi-dengan-perencanaan-yang-matang
- https://blog.advan.id/14564/data-analytics-mendukung-keputusan-investasi-untuk-menuju-investasi-cerdas-dan-menguntungkan/
- https://www.datacamp.com/blog/data-analytics-projects-all-levels
- https://thecleverprogrammer.com/2024/12/27/50-data-analysis-projects-with-python/
- https://www.interviewquery.com/p/data-analytics-project-ideas-and-datasets
- https://www.dataquest.io/blog/business-analyst-projects/
- https://tovtech.org/how-to-automate-powerpoint-presentations-using-python/
- https://idwebhost.com/blog/query-sql/
- https://i-3.co.id/8-tips-optimasi-query-pada-oracle-database/
- https://jptam.org/index.php/jptam/article/download/3269/2748/6268
- https://yunia.lecturer.pens.ac.id/Basis%20Data%20Lanjut/08%20-%20Optimasi%20Query.pdf
- https://badr.co.id/software-development/optimasi-database-mysql-untuk-performa-maksimal-di-aplikasi-node-js/
- https://journal.universitasmulia.ac.id/index.php/metik/article/download/8/17
- https://www.thrive.co.id/article/bagaimana-cara-menulis-sql-query-yang-kompleks-tanpa-pusing-simak-trik-ini
- https://www.qubisa.com/course/tips-jitu-mengelola-keuangan-pribadi-secara-efektif
- https://futureskills.id/blog/skill-mengelola-keuangan-kemampuan-penting-yang-wajib-kamu-miliki/
- https://www.fanruan.com/id/blog/data-analyst
- https://kelas.work/blogs/karier-financial-analyst
- https://careerfoundry.com/blog/data-analytics/data-analyst-salaries-by-industry/
- https://blog.myskill.id/tips-karir/financial-data-analyst-pengertian-30-pertanyaan-interview-tips-persiapan-dan-strategi-menjawab/